Wer die Google-Suche regelmäßig benutzt, weiß, dass sich in den organischen Suchergebnissen nicht nur Websites, sondern auch PDF-Dokumente finden. Tatsächlich befinden sich schon seit dem Jahre 2000 PDF-Dateien im Google-Index. Angeregt von einem aktuellen Post in Googles Blog möchten wir hier ergänzend zu den Vorschlägen von Google der Frage nachgehen, wie sich PDF-Dokumente aus SEO-Sicht optimieren lassen, um eine bessere Position in den Suchergebnissen zu erzielen.
Um zu verstehen, wie sich PDF-Dokumente optimieren lassen, stellen sich vorrangig zwei Fragen: Wie rankt Google PDF-Dokumente? Wonach entscheidet sich, welche Position sie im Vergleich zu Webseiten einnehmen? Und letztendlich auch: Was unterscheidet PDF-Dateien von Webseiten? Zwei Punkte fallen hier ins Auge: 1. PDFs sind meist länger und 2. Nutzer verlinken im Allgemeinen seltener auf PDF-Dokumente. Allgemein sagt auch Google selbst, dass die Beurteilung der Relevanz schwierig ist, da es auch vom persönlichen Geschmack abhängt, ob ein Nutzer lieber ein PDF oder eine Website lesen möchte. Die Handhabungen der verschiedenen Suchmaschinen unterscheiden sich und so können auch hier nur einige Hinweise gegeben werden, die hilfreich sein können.
Grundsätzliches: Google als textbasierte Suchmaschine benötigt echten Text, um ein Dokument optimal lesen und auswerten zu können. PDF-Dokumente bestehen dagegen häufig aus Bildern, besonders wenn es sich um gescannte Buchseiten o.ä. handelt. Mit Hilfe von OCR-Software (Optical Character Recognition – eine Technologie, die vielen vom Scanner bekannt sein dürfte) wird Google zwar möglicherweise in Zukunft auch Bilder, die Text enthalten, besser auslesen können, doch bis es so weit ist, sind reine Textdokumente die bessere Wahl. Überprüfen lässt sich dies sehr einfach: kann der Text aus einem PDF-Dokument per Copy & Paste in eine Word-Datei kopiert werden, handelt es sich um echten Text. Um Google den Zugriff zu ermöglichen, sollten PDF-Dateien außerdem weder verschlüsselt noch passwortgeschützt sein. Davon abgesehen lassen sich grundsätzlich die gleichen Regeln der Suchmaschinenoptimierung auf PDF-Dokumente anwenden, die auch für Websites gelten.
Dateiname und -größe: Analog zu Bildernamen und Website-URLs sollte der Dateiname von PDF-Dokumenten Keywords enthalten, die durch einen Bindestrich voneinander getrennt werden. Auch bei PDFs sollte die Dateigröße zudem so gering wie möglich gehalten werden. Besonders eingebundene Bilder können Dateien schnell auf ein Vielfaches ihrer ursprünglichen Größe anwachsen lassen. Hier sollten die Bilder vorher optimiert werden, um einige kB einzusparen.
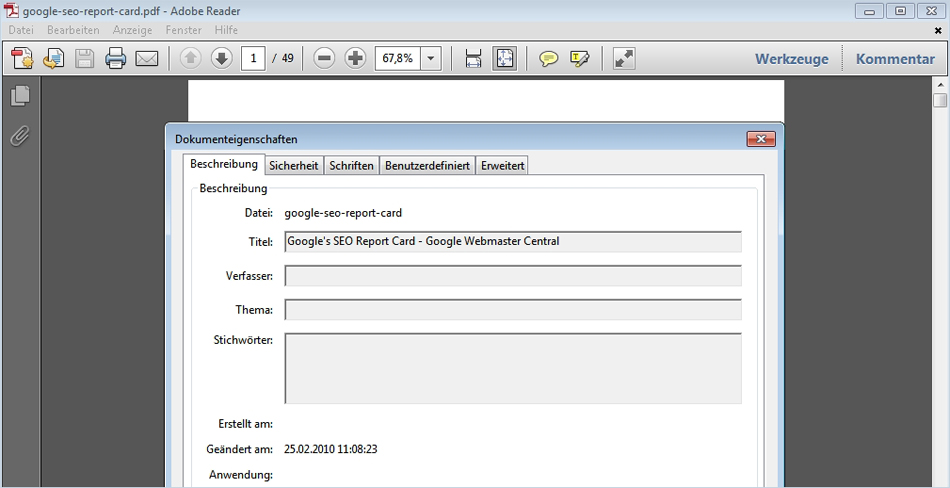
Seitentitel: Der Seitentitel des Dokuments (zu finden in den Dokument-Eigenschaften) sollte die relevanten Keywords enthalten, jedoch nicht zu lang sein. Meist bildet der Titel in den Suchergebnissen die Überschrift. Im Gegensatz zu Websites gibt es hierzu jedoch folgende Abweichung bei Google: Der Seitentitel kann durch Linktexte externer Links ersetzt werden. Um zumindest die eigenen Links auf das Dokument zu optimieren, sollte hier unbedingt auf relevante Keywords geachtet werden. (Wie bei @-web zu lesen war, scheint Google jedoch auch für Websites mit eigenen Seitentiteln zu experimentieren, die Regel ist das jedoch nicht.)
Thema und Keywords: In dieser Meta-Angabe sollte das Dokument inhaltlich zusammengefasst werden und Nutzer dazu anregen, auf den Treffer zu klicken, denn analog zur Meta-Description wird dieser Text als Beschreibung in den Suchergebnissen angezeigt. Keywords können ausgefüllt werden, spielen jedoch wie bei Websites keine große Rolle mehr für das Ranking.
Überschriften und Text: Wie auch bei Websites gliedern die Überschriften in einem PDF-Dokument den Inhalt und werden von der Suchmaschine besonders beachtet. Hier sollten also relevante Keywords untergebracht werden. Auch im Dokument selbst sollten die wichtigsten Keywords im Inhalt zu finden sein.
Autor: Seit einiger Zeit interessiert sich Google auch für den Autor eines Dokuments. Prominente Autoren schaffen Vertrauen, der Nutzer erhält außerdem in den Suchergebnissen eine weitere Information über das gefundene Dokument, indem ein Foto des Autors rechts neben dem Treffer eingeblendet wird. Den Autor eines PDF-Dokuments einzutragen kann also sinnvoll sein, da einem Treffer mit Autorenbild im Allgemeinen mehr Aufmerksamkeit geschenkt wird.
Verlinkung: Linktexte sind auch in PDF-Dokumenten relevant. Ebenso vererben Links aus PDF-Dokumenten PageRank. Der größte Unterschied zu Links aus Websites besteht derzeit darin, dass es nicht möglich ist, innerhalb eines PDF-Dokuments einen Link mit dem Attribut „rel=nofollow“ zu versehen. Natürlich sollte auch das PDF selbst auf den eigenen Seiten mit einem relevanten Linktext verlinkt werden.
Usability: Im Sinne einer hohen Nutzerfreundlichkeit empfiehlt es sich besonders bei langen Dokumenten mit einer Navigation zu arbeiten. Für das Layout ist die Darstellung als „single page“ optimal.
Duplicate Content: Stellen PDF-Dateien eine 1:1 Kopie einer Website dar, sollte durch den „canonical“-Tag das Original gekennzeichnet werden.
PDF-Dokumente vom Indexieren ausschließen: Möchte man den Googlebot davon abhalten, ein PDF-Dokument in den Index aufzunehmen, hilft die Angabe “noindex” im HTTP-Header. Dateien, die schon indexiert sind, werden durch diese Maßnahme nach einiger Zeit ebenfalls aus dem Index entfernt. Um den Prozess zu beschleunigen, kann das URL Removal Tool in den Google Webmaster Tools benutzt werden. Wichtig ist an dieser Stelle auch der Hinweis, dass eine große Anzahl an PDFs zu vermeiden ist, da dies eher den Anschein von automatisch generiertem Content macht.
Weitere Hinweise zur Optimierung von PDF-Dokumente finden sich auch in der 31. Ausgabe des Suchradars.